################## MSE
import numpy as np
actual = np.random.randint(0, 10, 10)
predicted = np.random.randint(0, 10, 10)
print('Actual :', actual)
print('Predicted :', predicted)
ans = []
# The Computation through applying Equation
for i in range(len(actual)):
ans.append((actual[i]-predicted[i])**2)
MSE = 1/len(ans) * sum(ans)
print("Mean Squared error is :", MSE)
################### MAE
import numpy as np
actual = np.random.randint(0, 10, 10)
predicted = np.random.randint(0, 10, 10)
print('Actual :', actual)
print('Predicted :', predicted)
ans = []
# The Computation through applying Equation
for i in range(len(actual)):
ans.append((actual[i]-predicted[i])**2)
MAE = 1/len(ans) * sum(ans)
print("Mean Absolute error is :", MAE)
###################### Huber Loss
import numpy as np
def huber_loss(y_pred, y, delta=1):
huber_mse = 0.5*np.square(np.subtract(y,y_pred))
huber_mae = delta * (np.abs(np.subtract(y,y_pred)) - 0.5 * delta)
return np.where(np.abs(np.subtract(y,y_pred)) <= delta, huber_mse, huber_mae).mean()
actual = np.random.randint(0, 10, (2,10))
predicted = np.random.randint(0, 10, (2,10))
print('actual :', actual)
print('predicted :', predicted)
print("Mean Absolute error is :", huber_loss(actual, predicted))Intelligence et al.
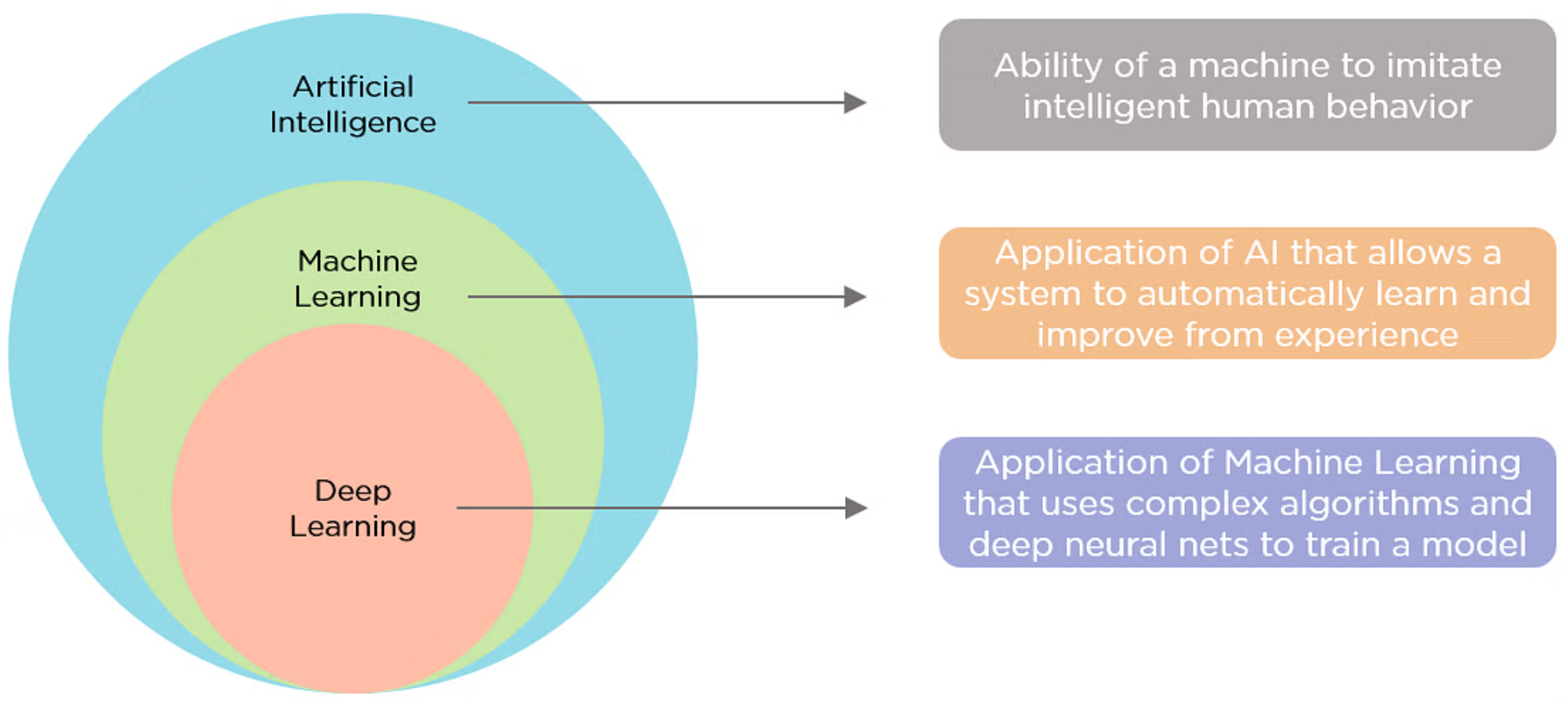 Source:https://www.simplilearn.com/ice9/free_resources_article_thumb/AIvsML.png
Source:https://www.simplilearn.com/ice9/free_resources_article_thumb/AIvsML.png
History of AI

Another Look

GPT and after

Statistics and AI (Two Cultures)

Statistics and AI (Two Cultures)

MNIST Data

A typical neuron
- Gross physical structure
- There is one axon that branches
- There is a dendritic tree that collects input from other neurons.
- Axons typically contact dendritic trees at synapses
- A spike of activity in the axon causes charge to be injected into the post-synaptic neuron.
- Spike generation
- There is an axon hillock that generates outgoing spikes whenever enough charge has flowed in at synapses to depolarize the cell membrane.

Linear neurons
- These are simple but computationally limited
- If we can make them learn we may get insight into more complicated neurons.

Linear neurons
- These are simple but computationally limited
- If we can make them learn we may get insight into more complicated neurons.


Binary threshold neurons
- McCulloch-Pitts (1943)
- First compute a weighted sum of the inputs.
- Then send out a fixed size spike of activity if the weighted sum exceeds a threshold.
- McCulloch and Pitts thought that each spike is like the truth value of a proposition and each neuron combines truth values to compute the truth value of another proposition!

Binary threshold neurons
- There are two equivalent ways to write the equations for a binary threshold neuron.

Rectified Linear Neurons
You have heard of RELU
- They compute a linear weighted sum of their inputs.
- The output is a non-linear function of the total input.

Sigmoid neurons
- These give a real-valued output that is a smooth and bounded function of their total input.
- Typically they use the logistic function
- They have nice derivatives which make learning easy.

Stochastic binary neurons
- These use the same equations as logistic units.
- But they treat the output of the logistic as the probability of producing a spike in a short time window.
- We can do a similar trick for rectified linear units:
- The output is treated as the Poisson rate for spikes.

A very simple way to recognize handwritten shapes
- Consider a neural network with two layers of neurons.
- neurons in the top layer represent known shapes.
- neurons in the bottom layer represent pixel intensities.
- A pixel gets to vote if it has ink on it.
- Each inked pixel can vote for several different shapes.
- The shape that gets the most votes wins.

Display the weights

Give each output unit its own “map” of the input image and display the weight coming from each pixel in the location of that pixel in the map.
Use a black or white blob with the area representing the magnitude of the weight and the color representing the sign.
Why the learning procedure works (first attempt)
- Consider the squared distance between any feasible weight vector and the current weight vector.
- Example: Every time the perceptron makes a mistake, the learning algorithm moves the current weight vector closer to all feasible weight vectors.

Understanding Residuals

Understanding Residuals

Understanding Loss

Regression Loss Functions

Classification Loss Functions

Gradient Descent

Gradient Descent

Gradient Descent

Source: https://datascience.stackexchange.com/questions/44703/how-does-gradient-descent-and-backpropagation-work-together
Optimization issues in using the weight derivatives
- How often to update the weights
- Online: after each training case.
- Full batch: after a full sweep through the training data.
- Mini-batch: after a small sample of training cases.
- How much to update
- Use a fixed learning rate?
- Adapt the global learning rate?
- Adapt the learning rate on each connection separately?
- Don’t use steepest descent?

A simple example of overfitting

- Which model do you trust?
- The complicated model fits the data better.
- But it is not economical.
- A model is convincing when it fits a lot of data surprisingly well.
- It is not surprising that a complicated model can fit a small amount of data well.
Feed-forward neural networks
- These are the common type of neural network in practical applications.
- The first layer is the input and the last layer is the output.
- If there is more than one hidden layer, we call them “deep” neural networks.
- They compute a series of transformations that change the similarities between cases.

Recurrent networks
- These have directed cycles in their connection graph.
- That means you can sometimes get back to where you started by following the arrows.
- They can have complicated dynamics and this can make them very difficult to train.
- There is a lot of interest at present in finding efficient ways of training recurrent nets.

Recurrent nets with multiple hidden layers are just a special case that has some of the hidden\(\rightarrow\)hidden connections missing.
The standard paradigm for statistical pattern recognition
- Convert the raw input vector into a vector of feature activations. Use hand-written programs based on common-sense to define the features.
- Learn how to weight each of the feature activations to get a single scalar quantity.
- If this quantity is above some threshold, decide that the input vector is a positive example of the target class.
The standard Perceptron architecture

Softmax


ANI, AGI, ASI

Towards ASI

System Design for Road Users

System Design for Road Users

System Design for Road Users

System Design for Road Users

System Design for Road Users

System Design for Road Users

AI World Models

Deep Learning
- Transportation
- Driving assistance / autonomous driving
- On-line Safety / Security
- Filtering harmful/hateful content
- Filtering dangerous misinformation
- Environmental monitoring
- Medicine
- Medical imaging
- Diagnostic aid
- Patient care
- Drug discovery


Future of AI
- Understand the world, understand humans, have common sense
- Level-5 autonomous cars
- That learn to drive like humans, in about 20h of practice
- Virtual assistants that can help us in our daily lives
- Manage the information deluge (content filtering/selection)
- Understands our intents, takes care of simple things
- Real-time speech understanding & translation
- Overlays information in our AR glasses.
- Domestic Robots
- Takes care of all the chores
- For this, we need machines near-human-level AI
- Machines that understand how the world works

How could machines learn like animals and humans?

- How do babies learn how the world works?
- How can teenagers learn to drive with 20h of practice?
Modular Architecture for Autonomous AI
- Configurator
- Configures other modules for task
- Perception
- Estimates state of the world
- World Model
- Predicts future world states
- Cost
- Compute “discomfort”
- Actor
- Find optimal action sequences
- Short-Term Memory
- Stores state-cost episodes

Mode-2 Perception-Planning-Action Cycle
- Akin to Model-Predictive Control (MPC) in optimal control.
- Actor proposes an action sequence
- World Model imagines predicted outcomes
- Actor optimizes action sequence to minimize cost
- e.g. using gradient descent, dynamic programming, MC tree search…
- Actor sends first action(s) to effectors

Self-Supervised Learning = Learning to Fill in the Blanks
- Reconstruct the input or Predict missing parts of the input.

This is a […] of text extracted […] a large set of […] articles

Self-Supervised Learning = Learning to Fill in the Blanks
- Reconstruct the input or Predict missing parts of the input.
This is a piece of text extracted from a large set of news articles

Learning Paradigms: information content per sample
- “Pure” Reinforcement Learning (cherry)
- The machine predicts a scalar reward given once in a while.
- A few bits for some samples
- Supervised Learning (icing)
- The machine predicts a category or a few numbers for each input
- Predicting human-supplied data
- 10→10,000 bits per sample
- Self-Supervised Learning (cake génoise)
- The machine predicts any part of its input for any observed part.
- Predicts future frames in videos
- Millions of bits per sample

The world is stochastic
- Training a system to make a single prediction makes it predict the average of all plausible predictions
- Blurry predictions!



The world is unpredictable. Output must be multimodal.
- Training a system to make a single prediction makes it predict the average of all plausible predictions
- Blurry predictions!

How do we represent uncertainty in the predictions?
- The world is only partially predictable
- How can a predictive model represent multiple predictions?
- Probabilistic models are intractable in continuous domains.
- Generative Models must predict every detail of the world
- My solution: JointEmbedding Predictive Architecture

Energy-Based Models: Implicit function
- Gives low energy for compatible pairs of x and y
- Gives higher energy for incompatible pairs

Energy-Based Models
- Feed-forward nets use a finite number of steps to produce a single output.
- What if…
- The problem requires a complex computation to produce its output? (complex inference)
- There are multiple possible outputs for a single input? (e.g. predicting future video frames)
- Inference through constraint satisfaction
- Finding an output that satisfies constraints: e.g a linguistically correct translation or speech transcription.
- Maximum likelihood inference in graphical models

Energy-Based Model: implicit function
- Energy function that captures the x,y dependencies:
- Low energy near the data points. Higher energy everywhere else.
- If y is continuous, F should be smooth and differentiable, so we can use gradient-based inference algorithms.

Energy-Based Model: unconditional version
- Conditional EBM: F(x,y)
- Unconditional EBM: F(y)
- measures the compatibility between the components of y
- If we don’t know in advance which part of y is known and which part is unknown


Energy-Based Models vs Probabilistic Models
- Probabilistic models are a special case of EBM
- Energies are like un-normalized negative log probabilities
- Why use EBM instead of probabilistic models?
- EBM gives more flexibility in the choice of the scoring function.
- More flexibility in the choice of objective function for learning
- From energy to probability: Gibbs-Boltzmann distribution
- Beta is a positive constant


Latent-Variable Generative EBM Architecture
- Latent variables:
- parameterize the set of predictions
- Ideally, the latent variable represents independent explanatory factors of variation of the prediction.
- The information capacity of the latent variable must be minimized.
- Otherwise all the information for the prediction will go into it.

Quarto
Quarto is an open-source scientific and technical publishing system that allows you to combine text, images, code, plots, and tables in a fully-reproducible document. Quarto has support for multiple languages including R, Python, Julia, and Observable. It works for a range of output formats such as PDFs, HTML documents, websites, presentations,…

GitHub
- GitHub is a good source for open source codes.
- Getting familiarity with a GitHub is a must.

GitHub: Make a fork

GitHub: Clone the repository

Papers with Code
